
线段树
基础知识
简介
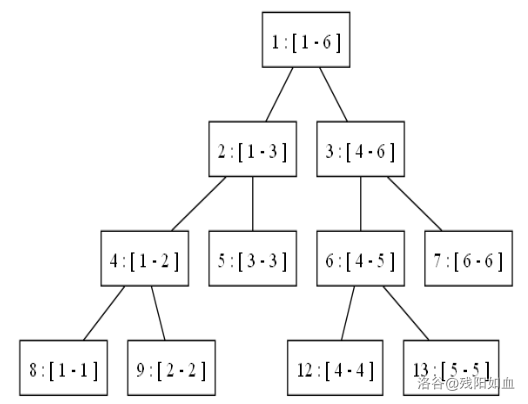
线段树是一颗不那么完全的二叉树。
设线段树有 h 层,则第 1 ∼ h − 1 层是满的,而第 h 层并不一定是满的,而是由第 h − 1 层的非叶子节点伸出两个儿子。
- 维护区间序列信息;
- 所有非叶子节点都有两个儿子
- 树上每个节点对应序列的一个区间
线段树是算法竞赛中常见的用来维护 区间信息 的数据结构。
编号方式
线段树是将序列分治的过程,并且将分治的过程记录下来。
根节点编号为 1,对应整个区间 [1, n]。
对于当前节点编号 u,对应区间 [l, r]。
令
- 左儿子编号 2 × u,对应区间 [l, mid];
- 右儿子编号 2 × u + 1,对应区间 [mid + 1, r];
- 父亲编号为
。
区间长度为 1 的线段树节点为叶子节点,没有左右儿子。
空间复杂度
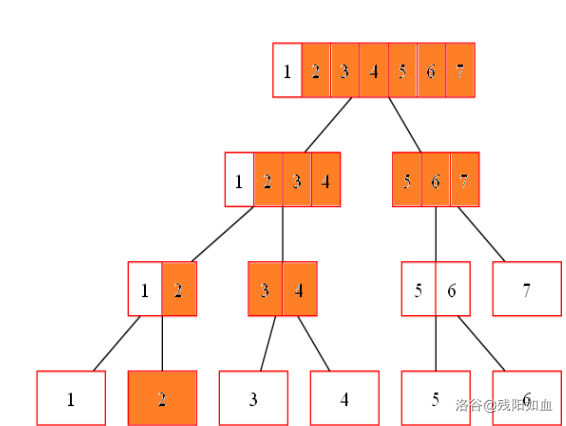
线段树是一个类似完全二叉树的结构,开空间时要为下面一层留足空间
考虑从上至下的每层节点数量之和,得到
1 + 2 + 4 + ⋯ + 2⌈log n⌉ ≤ 2⌈log n⌉ + 1 一般大小开到 4 × n 即可。
基本知识中,n 为区间长度的数量级。
更新
从子树更新信息返回时,我们需要合并子树所计算的信息。
什么时候需要调用呢?
- 询问时,我们没有修改子树的值,无需调用。
- 修改时,我们修改了子树的值,所有需要调用。
pushup() 的设计比较灵活,需要根据题目具体分析设计。
接下来的基本知识中,我们以区间求和与区间加上一个值来说明。
1 | void pushup(int u) { |
建树
我们令 w
数组存储其区间的所有数字之和。
- 当 l = r
即区间长度为 1 时,结束递归,赋值
w[u] = a[l]。 - 当 l ≠ r 即区间长度大于 1 时,拆分为 [l, mid] 和 [r, mid] 两段,分别递归,最后合并。
建树时每个节点都只会被访问一次,时间复杂度 O(n)。
1 | void build(int u, int l, int r) { |
单点操作
单点查询
晚点写。
单点修改
晚点写。
区间操作
区间定位
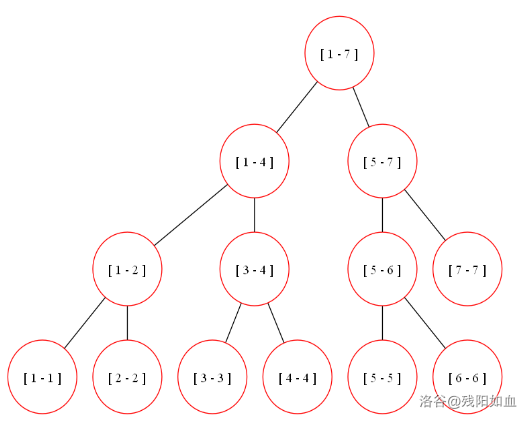
如何定位需要的区间?
假设当前递归到的区间为 [l, r],目标区间为 [L, R],那么要分类讨论:
- 如果 [l, r] 与 [L, R] 没有交集,即 r < L 或 l > R 时,直接返回即可;
- 如果 [l, r] 被
[L, R] 完全包含,即
l ≥ L 且 r ≤ R 时,由于已经使用
w记录了,直接返回存储的值即可; - 否则,将其拆分为 [l, mid] 和 [mid + 1, r] 两部分,分别进行递归。
如图,[2, 2], [3, 4], [5, 7] 就是我们需要的区间。
故我们需要两个判断区间关系的函数:
1 | // 当前递归到的区间为 [l,r],目标区间为 [L,R],后面代码中均用这个意义 |
区间查询
按照区间定位找到每一个需要的区间,将其值累加返回即可。
复杂度证明
在区间查询中,并不是每一层只会向下延申一个节点,而是对左右节点分别递归。在线段树每层的递归中,最多只有两个节点会向下继续递归,也就是被查询区间两端点所在的节点。而剩下的节点要么被完全包含,要么与查询区间无交。因此,每一层只会新建两个递归函数。而因为树高为 log n,所以时间复杂度为 O(log n)。
区间修改
如果对于每一个区间中的叶子节点进行操作,然后逐渐合并回到根节点时,访问的数量与节点总数量同级,时间复杂度为 O(n),较劣。如何优化呢?
晚点写。
题目分析
线段树 - 题单 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
提高 1 例题
【模板】线段树 1
就是基础知识的分析了。代码见上面的分析。
【模板】线段树 2
思路分析
由于题目中出现了两种操作:×, +,所以我们需要多个懒标记。
记 w 表示区间和,lzy_add
表示加法的懒标记,lzy_mul 表示乘法的懒标记。
lzy_add初始化为 0,因为开始时没有需要添加的数。lzy_mul初始化为 1,因为对于一个数 x,有 x = 1 × x,所以乘的值默认为 1。此外,由于更新lzy_mul时是(lzy_mul[u] *= x) %= m,如果初始为 0 的话需要进行特判,比较麻烦。
记录一个点的真实值为 w × lzy_mul + lzy_add。
为什么这样记录?
- 记为 (
w+lzy_add) ×lzy_mul。此时非常不容易进行更新操作,并且在lzy_add变化后,为了消除 Δlzy_add×lzy_mul的影响,lzy_mul要对应减小,可能变为小数,精度损失严重。- 记为
w×lzy_mul+lzy_add。此时改变lzy_add时与lzy_mul没有关联,且lzy_mul变化后根据分配律lzy_add× Δlzy_mul即可。
区间加 x 即得
w×lzy_mul+lzy_add+ x,直接将 x 加到加法标记上即可。区间乘 x 即得 (
w×lzy_mul+lzy_add) × x ⇒w×lzy_mul× x +lzy_add× x,因此要给乘法标记和加法标记都乘上 x。
由于一个点的真实值为 w × lzy_mul + lzy_add,所以:
- 原来值为
w; - 下放乘法标记,
w⇒w×lzy_mul; - 下放加法标记,
w×lzy_mul⇒w×lzy_mul+lzy_add。
由此可知,下方标记时先下放乘法标记,再下方加法标记。
时间复杂度:建树 O(n),q 次操作,每次操作 O(log n),所以复杂度为 O(n + qlog n)。
核心代码
1 | // build() 遍历到每一个节点时也要 lzy_mul[u] = 1; |